Safe and Synchronized Reconfiguration Protocol
While the previous work on application-centric resource management addressed the coordination of multiple applications and network segments, it so far lacked detailed descriptions on how safety can actually be achieved given such a resource management approach. The reconfiguration protocol proposed here addresses these concerns, deriving constraints and requirements from a widely applicable system model that includes vehicle dynamics
The main challenges with respect to the coordination of applications can be summarized as follows:
- Applications are subject to stringent timing and safety guarantees that must not be violated.
- Cross-interference (dependencies) and competition for channel resources between applications may pose significant harm to those safety constraints.
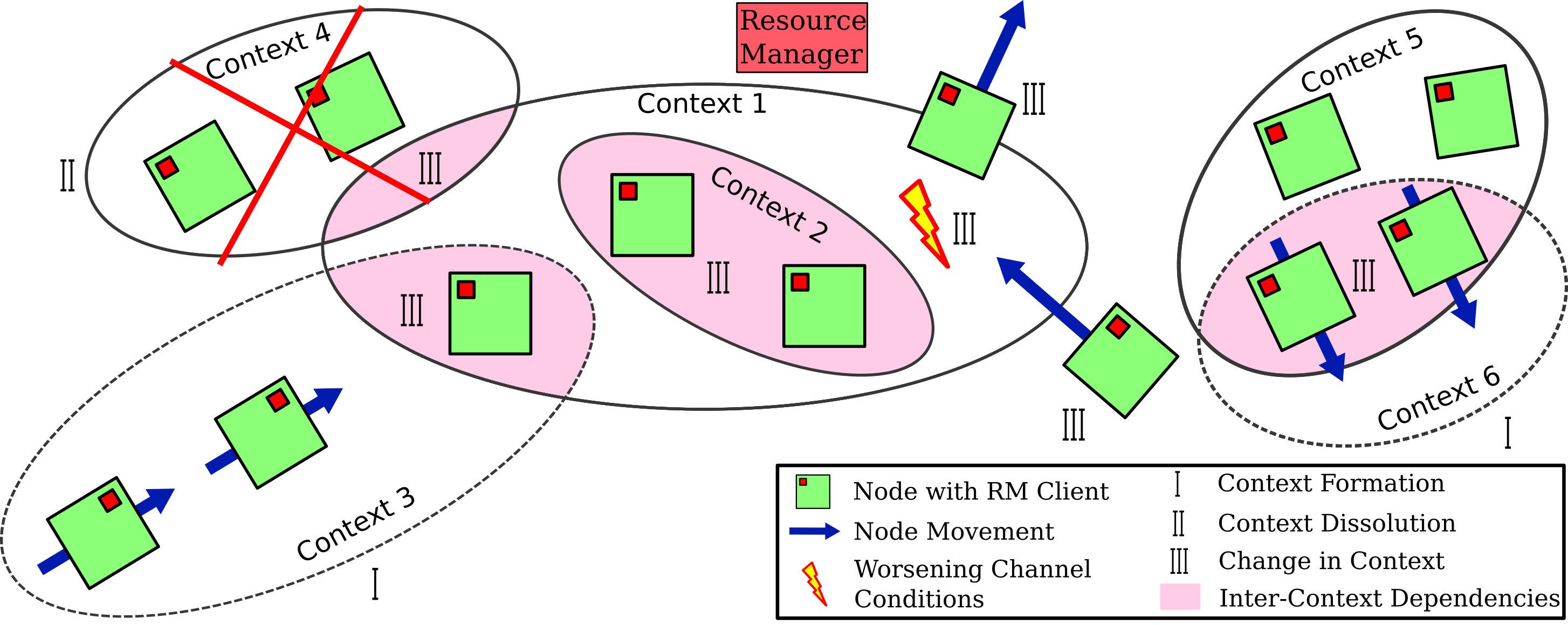
- Dynamic environments where connection quality can fluctuate on a per node basis or where nodes may join or leave an application context group (a set of nodes exchanging data) as visualized in Figure 1 complicate the issue.
- Consistent application modes must be ensured at all time, even if changes are necessary
The reconfiguration protocol (cf. Figure 2) is based on two components:
- A heartbeat-based safety layer that continuously monitors connection between the RM and all application entities
- A four phase synchronized reconfiguration protocol
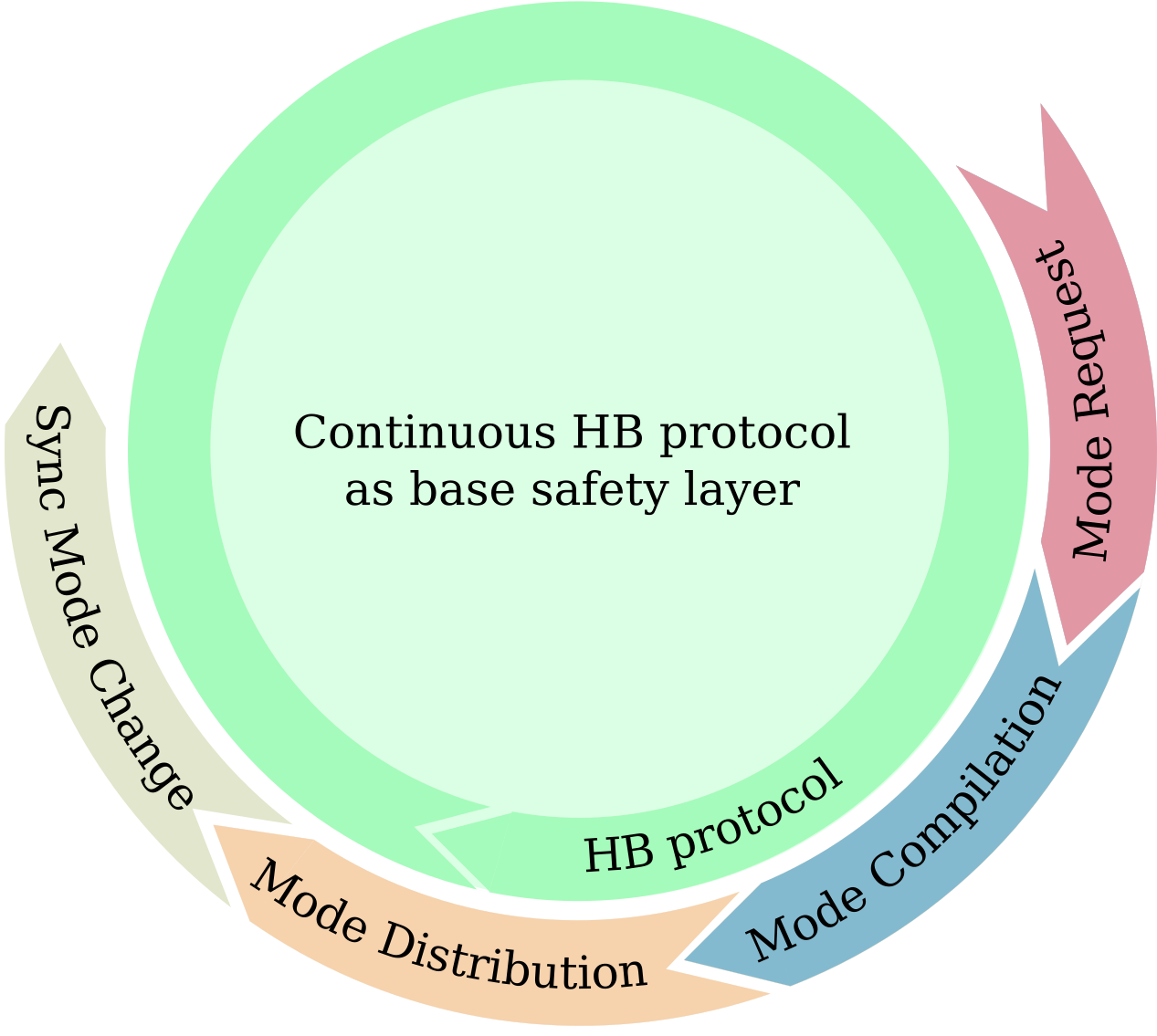
The low-overhead heartbeat-based connection monitoring ensures that applications that lose connection to the RM, i.e., cannot be controlled by the RM, seize data exchange immediately in an attempt to prevent unbounded interference to other applications. With the continuous HB protocol addressing basic safety requirements, the reconfiguration protocol must only handle request-triggered reconfiguration of all applications. Here, it is most important that a) the whole process finishes quickly and b) consistent modes and mode updates are performed, as otherwise safety could be seriously compromised. During the first phase, called Mode Request, entities issue requests towards the RM. Based on the request, the RM then compiles the parameter sets for the new mode during the Mode Compilation phase. Note that we assume near zero processing overhead for mode compilations as precomputation could be used for this step, reducing the phase to only selecting the next parameter sets. Next, the Mode Distribution phase is used by the RM to distribute the new mode’s parameter sets to all affected applications. Timeout-triggered retransmissions are used to tackle occasional message loss inherent to wireless communication. Finally, in order to ensure consistent modes, the new mode is activated in a Synchronized Mode Change across all applications. In case anything goes wrong during this process, the HB protocol kicks in, triggering applications to shut down prior to the synchronized mode change, thereby ensuring safety.
A prototype implementation (for Linux) has been developed and evaluated using a physical hardware demonstrator in combination with a FastDDS-based W2RP implementation. The experiments showed the reconfiguration protocol actually allowing for quick and synchronized reconfiguration while ensuring (in combination with the HB protocol) that critical applications are not subject to deadline violation, i.e., the services will not be interrupted in case of changes in channel conditions or context groups that require reconfiguration.
More details on the protocol as well as the experimental evaluation can be found within the paper.